

OLOCR:高精度图片和PDF文字识别工具
OLOCR 是一个高精度的图片和PDF文字识别(OCR)网站,支持多种语言和格式。您可以在网站上进行识别操作,而且所有的识别过程都在您的浏览器中进行,不会传输或保存您的图片和PDF文件。
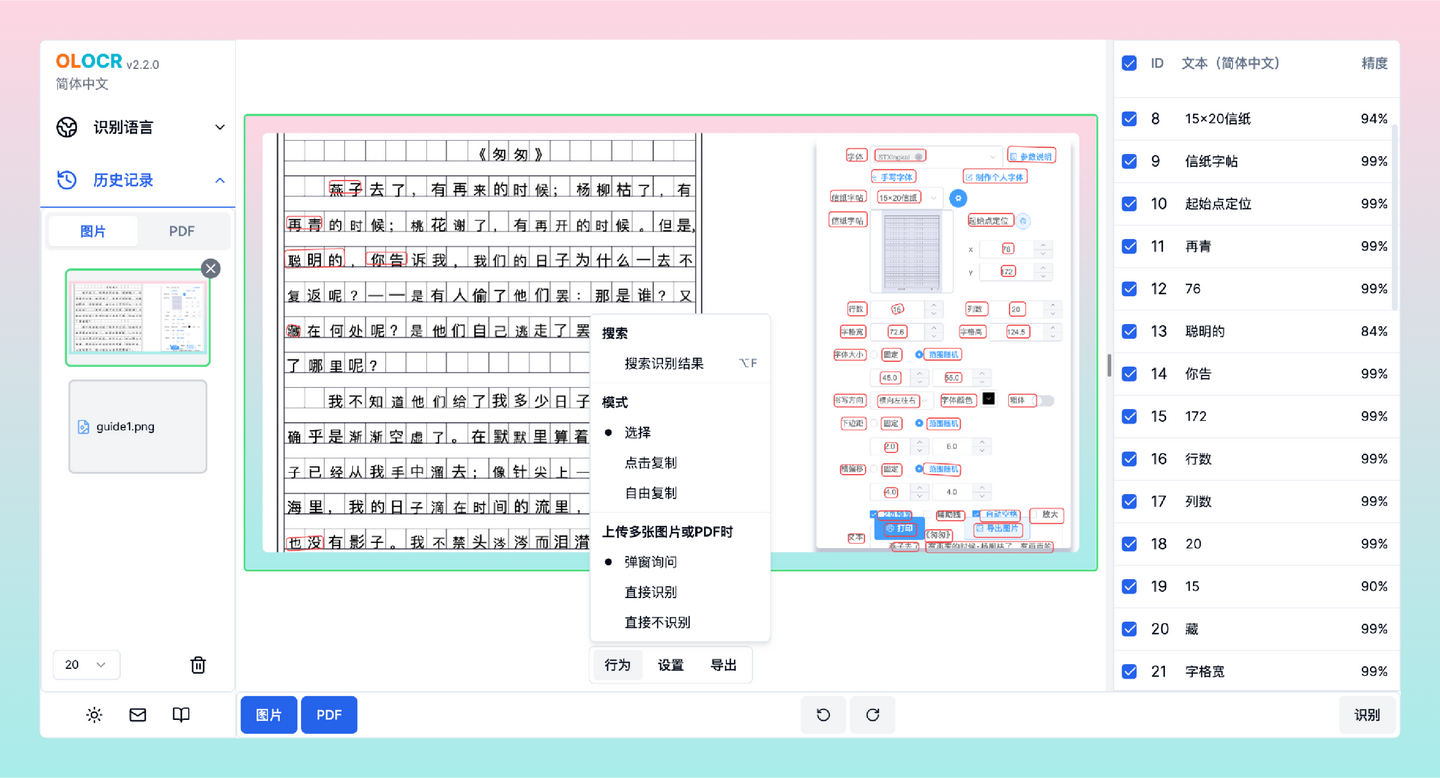
一、功能特征
-
支持多种语言:OLOCR 支持包括阿拉伯文、中文(简体和繁体)、英文、日文等在内的多种语言文字识别。
-
图片和PDF识别:您可以上传图片文件或PDF文件进行识别操作,无论是单张图片还是多页PDF,OLOCR 都能轻松应对。
-
多种识别模式:OLOCR 提供选择、点击复制和自由复制等多种识别模式,方便您根据实际需求进行操作。
-
识别结果导出:您可以将识别结果导出为.txt 或 .json 文件,方便后续的数据处理和使用。
-
可调节的识别速度:OLOCR 提供识别速度调节功能,根据您的需求可以选择快速识别或更精准的识别。
-
精度过滤和搜索:根据您的需要,可以根据识别精度过滤结果或进行搜索操作,以便更方便地查找和管理识别结果。
二、操作指南
- 打开 OLOCR 官网:https://olocr.com/
- 选择要识别的语言:在页面上选择识别语言,确保选择正确的目标识别语言。
- 上传图片或PDF:点击页面上的上传按钮,选择要识别的图片或PDF文件。
- 等待识别:系统会进行识别操作,在首次加载时可能需要一些时间。
- 修改纠正识别结果(可选):如果发现识别有误的文本,您可以点击表格中的文本进行修改和纠正。
- 导出识别结果:一旦识别完成,您可以选择导出识别结果为.txt 或 .json 文件。
三、支持平台
OLOCR 是基于网页的在线工具,可以在支持浏览器的各种操作系统和设备上使用。
四、产品定价
OLOCR 是免费使用的在线工具,您可以随时访问官网进行文字识别操作,无需支付任何费用。
五、使用场景
OLOCR 的高精度和多语言支持使其在各种场景下都能发挥作用,包括但不限于:
-
文字提取:从图片或PDF中提取文字内容,方便编辑、引用或翻译。
-
文档数字化:将纸质文档或扫描件转换为可编辑的电子文档。
-
数据处理:将大量的图片或PDF数据批量转换为可搜索和可管理的文本数据。
-
学习和研究:方便学生、研究人员从图书、论文或资料中提取关键信息。
六、运作模式
OLOCR 的运作模式非常简单和安全。所有的识别操作都在您的浏览器中进行,不会传输或保存您的图片和PDF文件。这意味着您的隐私得到了保护,您完全掌控识别过程和识别结果。
结语
OLOCR 是一款功能强大而又易于使用的图片和PDF文字识别工具。它支持多种语言和格式,具备高精度和良好的识别效果。无论是个人用户还是专业人士,都能从 OLOCR 中受益。访问 OLOCR官网,体验高效便捷的文字识别服务。
官网网站:https://olocr.com/