

Clipper:一个开源的HTML到Markdown转换器和爬虫工具
Clipper是一个开源工具,旨在帮助用户从网页中提取关键内容并将其转换为Markdown格式。它还提供了爬虫功能,可以用于收集整个网站的内容。
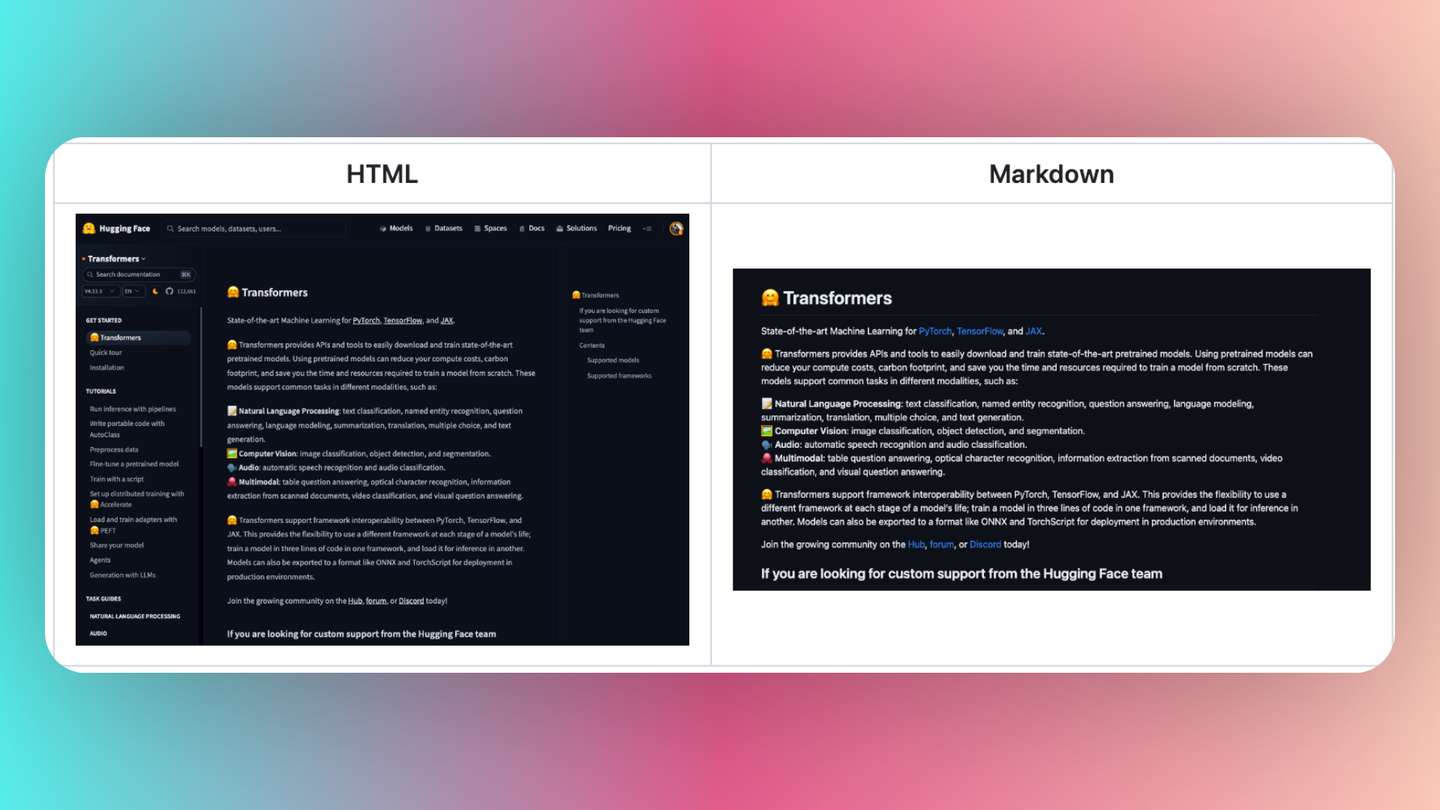
一、功能特征
-
轻松剪辑 Web 内容并将其转换为 Markdown:Clipper可以从网页或HTML文档中提取内容,并将其转换为Markdown格式,方便用户进行进一步处理和使用。
-
支持 URL 和文件输入:Clipper可以直接从指定的URL或本地文件中提取内容,并进行转换。
-
全面网站内容收集的爬网功能:Clipper提供了爬虫功能,可以自动遍历网站的多个页面,并将其内容剪辑并转换为Markdown格式。
-
可选输出格式:Clipper支持将提取的内容输出为Markdown或JSON格式,用户可以根据自己的需求选择合适的输出格式。
-
无需浏览器扩展:与Evernote Web Clipper或Notion Web Clipper等浏览器扩展不同,Clipper完全在终端上运行,无需安装任何扩展或注册账户。
二、操作指南
使用Clipper非常简单,以下是基本的操作指南:
| 操作 | 命令 | 说明 |
|---|---|---|
| 安装Clipper | npm install -g @philschmid/clipper | 使用npm安装Clipper |
| 从URL剪辑内容 | clipper clip -u |
从URL剪辑内容并转换为Markdown格式 |
| 从文件剪辑内容 | clipper clip -i |
从文件剪辑内容并转换为Markdown格式 |
| 爬取网站内容 | clipper crawl -u |
进行网站爬取并剪辑所有页面 |
| 输出为Markdown格式 | clipper clip -u |
将剪辑的内容输出为Markdown格式 |
| 输出为JSON格式 | clipper clip -u |
将剪辑的内容输出为JSON格式 |
三、支持平台
Clipper是一个基于Node.js的工具,可以在各种支持Node.js的平台上运行,包括Windows、macOS和Linux。
四、产品定价
Clipper是开源工具,可以免费使用。
五、使用场景
Clipper可以在以下场景中发挥作用:
-
网页内容提取:从多个网页中提取关键信息,并将其转换为Markdown格式,方便进一步处理和分析。
-
数据准备:为训练模型或提供数据给RAG模型,可以使用Clipper从网页或HTML文档中提取数据,并将其转换为适合模型训练的格式。
-
内容整理和归档:Clipper可以帮助用户将喜欢的网页内容剪辑并转换为Markdown格式,方便进行整理、归档和个人笔记。
六、运作模式
Clipper的运作模式如下:
-
输入网页或HTML文档:用户可以提供要剪辑的网页URL或本地HTML文件。
-
内容提取和转换:Clipper使用Mozilla的Readability库和Turndown库来提取网页内容并将其转换为Markdown格式。
-
输出结果:Clipper将转换后的Markdown内容保存到指定的输出文件中,用户可以根据需要选择输出格式为Markdown或JSON。
结语
Clipper是一个功能强大且灵活的HTML到Markdown转换器和爬虫工具,它可以帮助用户轻松提取和转换网页内容。无论是进行数据准备还是进行内容整理,Clipper都是一个方便实用的工具。它的简单操作和支持多平台的特点使其成为许多用户的首选工具。无论是从单个网页中提取信息,还是爬取整个网站的内容,Clipper都能快速且准确地完成任务。通过将提取的内容转换为Markdown格式,用户可以更方便地进行进一步处理、分析和分享。使用Clipper,您可以有效地提升RAG模型的信息库,提高生成的文本的准确性和相关性。